Syniti, Infinite Potential Unlocked

Datenintegration mit Kafka
Optimieren Sie Ihre Datenintegration mit Kafka
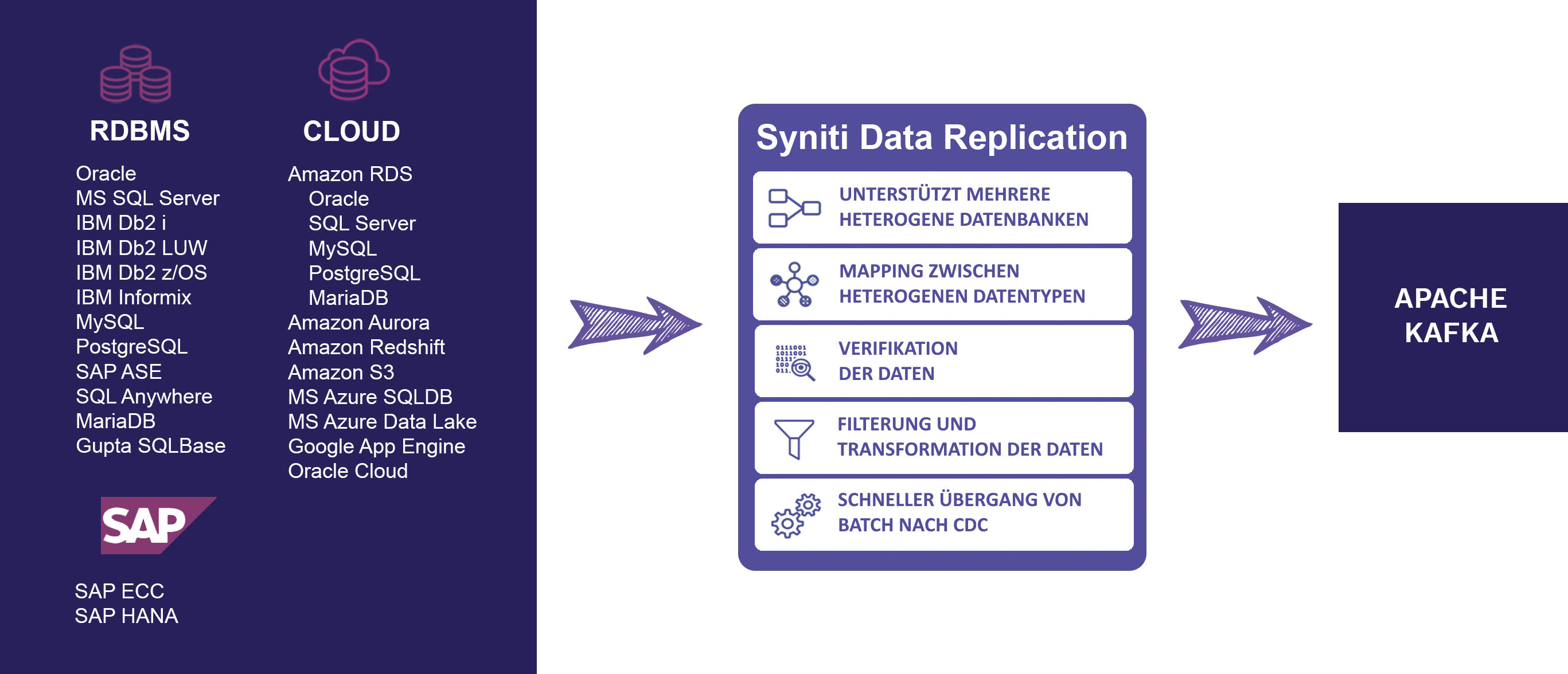
Syniti Data Replication lädt mit hoher Geschwindigkeit und in Echtzeit von mehreren Systemen
Syniti Data Replication (ehemals DBMoto) ist die ideale Lösung für die sichere, schnelle und einfache Integration von Echtzeitdaten aus heterogenen Datenbanken in Apache Kafka-Systeme..
Apache Kafka ist die Hauptalternative für die Kommunikation von Informationsströmen, die mit hoher Geschwindigkeit generiert werden und von einer oder mehreren Anwendungen verwaltet werden müssen, die für Messaging-Dienste (ActiveMQ- oder RabbitMQ-Typ), Stream-Verarbeitung und Web-Tracking verwendet werden können oder für operationale Traces.
Eines der Hauptmerkmale von Kafka ist seine Geschwindigkeit bei der Verarbeitung von Nachrichten. Um ein Gleichgewicht zwischen den von Kafka empfangenen und den verarbeiteten Daten zu gewährleisten, ist eine Lösung erforderlich, mit der Daten aus relationalen Datenbanken oder Cloud-Systemen übertragen werden können.
Testen Sie Syniti Data Replication mit Ihren Kafka-Systemen
Laden Sie eine Testversion herunter. Technischer Support in diesem Zeitraum inbegriffen.
Systemanforderungen:
Windows Server 2019/2016/2014/2012/2008/2003 | .NET Framework 4.0 oder höher
Windows Server 2019/2016/2014/2012/2008/2003 | .NET Framework 4.0 oder höher

Reduziert das Risiko des Datenverlusts während der Übertragung oder aufgrund von Systemabstürzen
Schnelle, einfache und problemlose Implementierung

Zuverlässige und aktuelle Daten für Ihre Kafka-Systeme

Reduzieren Sie die finanziellen Auswirkungen auf Ihre Apache Kafka-Umgebung
Haupteigenschaften:
- Transaktionsdatenreplikation durch Change Data Capture
- Snapshot-Replikation für massive Datenlasten
- Umfassende Unterstützung für Cloud-Systeme als Datenquelle
- Verifer™, integrierte Lösung für die Datenprüfung
- Nicht-invasives Produkt, installiert keine Agenten oder Komponenten in Datenbanksystemen
- Offene APIs um Syniti Data Replication in Ihre Architekturen oder Lösungen von Drittanbietern zu integrieren
- Vollständige Aufzeichnung der Aktivitäten und Verfügbarkeit
- Automatische Erstellung von Tabellen im Ziel
- 100% grafische Lösung, ohne dass Code programmiert werden muss
- Schnelle und transparente Implementierung
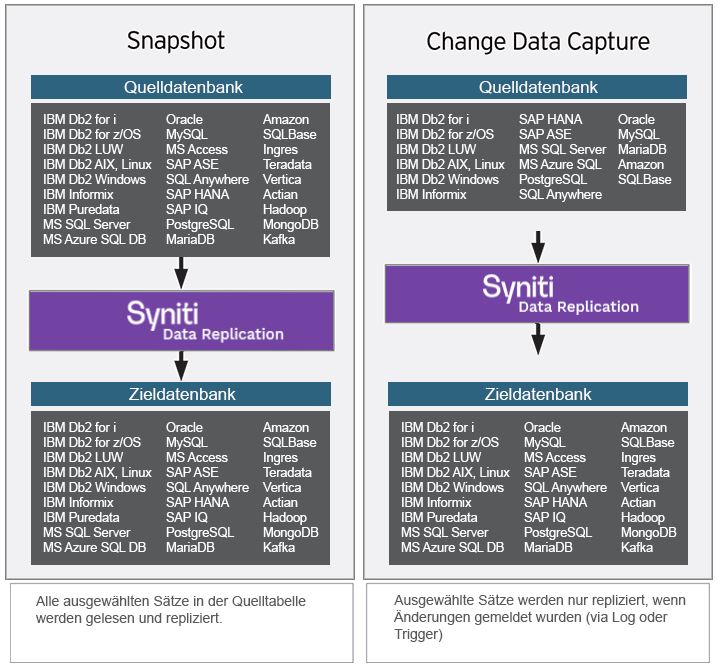
Zwei Arten der Datenreplikation für Kafka
- Refresh (Snapshot): Daten lesen, vom Benutzer definierte Zuordnungsregeln anwenden und das Ergebnis in die Zieldatenbank schreiben.
- Mirroring (CDC): Transaktionsreplikation von der Quelle zum Ziel mit CDC-Technologie, basierend auf der Verarbeitung von Transaktionsprotokollen, um ein höheres Maß an Präzision und Geschwindigkeit zu ermöglichen.
Unterstützte Datenbanken
• Oracle
• Microsoft SQL Server®
• Microsoft Azure SQL
• Microsoft Azure Data Lake
• IBM DB2 for i, AS400
• IBM DB2 for z/OS (OS/390)
• IBM DB2 LUW
• IBM Informix
• MySQL
• MariaDB
• PostgreSQL
• Snowflake
• Amazon
• Google
• SAP HANA
• SAP IQ
• SAP SQL Anywhere
• SAP ASE
• IBM PureData (Netezza)
• Vertica
• Teradata
• Hadoop
• MongoDB
• Apache Kafka
Testen Sie Syniti Data Replication mit Ihren Kafka-Systemen
Laden Sie eine Testversion herunter. Technischer Support in diesem Zeitraum inbegriffen.
Systemanforderungen:
Windows Server 2019/2016/2014/2012/2008/2003 | .NET Framework 4.0 oder höher
Windows Server 2019/2016/2014/2012/2008/2003 | .NET Framework 4.0 oder höher